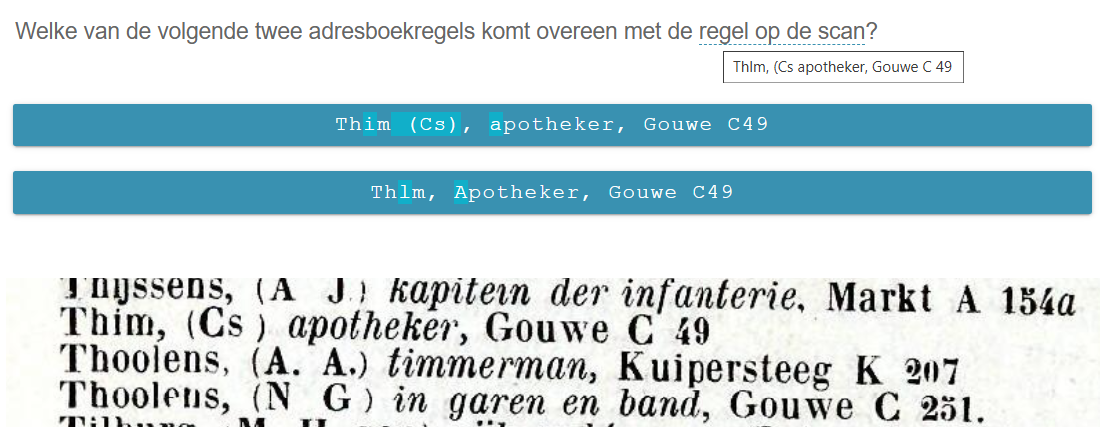
Uitleg adresboeken project
De Goudse adresboeken van 1867 tot en met 1950 zijn gescand en door middel van Optical Character Recognition (OCR) zijn de teksten herkend. Alhoewel de adresboeken hiermee doorzoekbaar worden zijn deze nog niet beschikbaar als data. Het doel van dit Vele Panden project is om de inwonerslijsten van de adresboeken om te zetten in data zodat we deze in de Gouda Tijdmachine kunnen koppelen.
Invulinstructie
- Neem over wat er in de bron staat, ook al is dit fout (dan niet corrigeren) of een afkorting (dan niet uitschrijven).
- Uitzonderingen: voer Co in als Co, vervang krul-aanhalingstekens als “ ” „ in als een eenvoudige " en krul-aanhalingstekens als ‘ ’ als een eenvoudige '.
- Neem punten en spaties over zoals de in de bron staan. Invoer die alleen verschilt in een punt of een spartie worden als gelijk geschouwd en komen niet in de controle.
- We willen de afzonderlijke delen uit de adresregel in losse velden krijgen. Wanneer er in de adresregel "Jong (wed. J. J. de)" staat komt er bij achternaam "Jong" en initialen (wed. J.J. de).
- Klik op de Markeer als probleem knop (de adresregel wordt dan overgeslagen en ook niet aan andere vrijwilligers aangeboden):
- als er in de invoer geen informatie (alleen "ruis") of te weinig informatie zit om te bepalen welke adresregel het betreft in het origineel;
- als er in de invoer 2 adressen lijken te zitten;
- als er in de invoer symbolen staan (bijv. een medaille) die je niet kunt invoeren. Tip:
 = het teken voor telefoon(nummer);
= het teken voor telefoon(nummer); - als er in de invoer meerdere adressen en/of telefoonnummers staan (komt vooral voor bij bedrijven met meerdere locaties).
Werkwijze
De in het OCR-proces herkende teksten zijn verzameld en opgeschoond. Deels handmatig, zodat er "adresboekregels" zijn die gecontroleerd / gecorrigeerd kunnen worden. Hierna zijn de adresboekregel met behulp van een slim algoritme opgeknipt in een 6-tal velden: de achternaam, de initialen (die veelal tussen () staan), het beroep (of bedrijf), de straat, de wijkletter en het nummer.
Als u aan de slag gaat krijgt u uit een willekeurig adresboek een adresregel voorgeschoteld. Aan de linkerkant de invoerveld met daarin de herkende tekstonderdelen en rechts de scan van de betreffende pagina uit het adresboek. Hier kunt u op inzoomen zodat de regel waar het om gaat goed in beeld is (dit werkt het snelst door het muiswieltje boven op uw muis te gebruiken) en dat de lichtblauwe 'lineaal' op de juiste regel staat (wanneer u op de Opslaan knop klikt zal de scan naar boven bewegen zodat de lichtblauwe 'lineaal' op de volgende regel komt).

Helemaal links boven staat de tekst die in het OCR-proces is herkend. Aan u de taak om te controleren of de 6 invoervelden correct zijn gevuld op basis van de scan en herkende tekst. Wanneer velden niet zijn herkend, dan is het betreffende invulveld geel gemarkeerd. In bovenstaand voorbeeld staat er bij beroep te veel tekst, die halen we weg. De wijkletter is niet ingevuld, hier vullen we L in (en niet I zoals in de herkende tekst staat!!). Dan klikt u op de 'Opslaan' knop en verschijnt de volgende adresregel. Veelal zal dit op dezelfde pagina van het adresboek zijn, dus de scan verandert niet.
NB: bij de start van de invoer staat de cursor automatisch in het eerste invoerveld (achternaam). Het de Tab-toets springt u naar het volgende invoerveld. Na het laatste invoerveld (Nummer) springt u met de Tab-toets naar de 'Opslaan' knop, die u met de Enter-toets ook kunt activeren.
Opletten!
Een deel van de te herkennen tekst bestaant uit cijfers. Het kan voorkomen dat u denkt, is dat nu een 3 of een 5? Sterker nog, vaak dacht de OCR-herkenning een 3 te zien in plaats van een 5.
Maar, veelal is het een 5, want de 3 wordt anders gedrukt (de OCR heeft het ook dikwijls mis!):
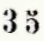
Omdat de OCR vaak ten onrechte een 3 herkende waar het eigenlijk een 5 is wordt het Nummer invulveld geel gemarkeerd als deze een 3 bevat. Een extra herinnering om het nummer goed te controleren.
Hoofdletters waar het ook opletten is, zijn de G en de C:
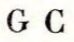
Tip: kopieertip
Soms heeft het slimme algoritme sommige velden niet weten te vullen. Hieronder een voorbeeld waar het beroep- en het straatveld leeg zijn. Aan u de taak om deze te vullen. U hoeft hierbij de tekst niet persé in te typen, want in dit geval is de tekst wel in het OCR-proces herkend zoals in het grijze 'Herkend' vlak is te zien. U kunt nu met de muis één of meer worden selecteren. Het selecteren van één woord kan heel snel door er op te dubbelklikken. Hierna klikt u op het invoerveld waar de betreffende tekst heen moet, zodra u klikt wordt de tekst er naartoe gekopieerd.

Tip: OCR invoer bekijken bij controle
Bij het controlere van adresregels die niet overeenkomen is het origineel altijd de eerste plek om te kijken. U kunt ook de door de computer herkende tekst (de OCR) bekijken, zet u muis daarvoor boven op de met stippellijn onderstreept "regel op de scan":